在 Macbook M1 上运行 AI 大模型 LLAMA

环境准备
在 MacBook 上本地运行大模型, 如要准备 Python 和 Xcode 以及 Git , 如果还没有安装的话, 按照下面的命令安装即可, 如果已经安装好了, 就可以跳过这两个步骤。
Python
Python 目前建议安装 3.10 版本, 各方面支持都比较完善。
brew install python@3.10
Python 安装好之后, 再安装 torch torchaudio torchvision , 命令如下:
pip3.10 install torch torchaudio torchvision
Xcode
Xcode 也是必须的, 因为接下来要从源代码编译 llama.cpp。 如果还没有安装 Xcode , 只要 Xcode 的命令行版本就可以, 在终端中输入下面的命令, 根据提示操作即可。
xcode-select --install
Git
除了基本的 Git 之外, 下载模型文件还需要 Git LFS , 可以用下面的命令一起安装:
brew install git git-lfs
完成之后, 输入下面的命令初始化 Git LFS :
git lfs install
下载 llama.cpp 源代码并编译
llama.cpp 对 M1 系列的 CPU 进行了专门的优化, 不仅可以充分发挥苹果 M1 芯片统一内存的优势, 而且能够调用 M1 芯片的显卡, 所以在 MacBook 上运行大模型, llama.cpp 是首选。
虽然 llama.cpp 提供编译好的二进制文件下载, 但是很多脚本和示例都在源代码中,因此还是需要克隆源代码下来并编译。
git clone git@github.com:ggerganov/llama.cpp.git
在 macOS 系统上, 只需要进入到 llama.cpp 目录, 然后执行 make 命令即可:
cd llama.cpp
make
llama.cpp 很活跃, 经常更新, 可以通过下面的命令更新并编译:
cd llama.cpp
git pull
make
其它系统可以参照 llama.cpp 的 说明 进行编译。
下载模型
模型就要根据自己电脑的配置有选择的下载, 对于个人电脑来说, 一般是 7b/13b/34b 参数的模型, 再多参数的模型就没必要下载了, 不仅体积庞大,费时费力, 而且在个人电脑上几乎无法运行。
我的 MacBook 的配置是 M1 Max 64G + 1T , 最多可将 50G 左右的内存做显存使用, 最终保留了下面几个模型文件, 仅供参考。
- CodeLlama-7b-Instruct-hf
- CodeLlama-13b-Instruct-hf
- CodeLlama-13b-Python-hf
- Phind/Phind-CodeLlama-34B-v2
- 01-ai/Yi-34B-200K
以 CodeLlama-7b-Instruct-hf 为例, 下载命令为:
# 确认 git lfs 已经安装
git lfs install
# 在中国大陆从 huggingface 下载模型需要代理
export HTTPS_PROXY=socks5://127.0.0.1:1080
export HTTP_PROXY=socks5://127.0.0.1:1080
export ALL_PROXY=socks5://127.0.0.1:1080
# 下载模型文件
git clone --progress git@hf.co:codellama/CodeLlama-7b-Instruct-hf codellama-7b-instruct-hf
接下来就是等待, 考验代理的稳定性与速度的时刻到了。 如果中途下载失败, 输入下面的命令可以继续, 不需要重新开始:
cd codellama-7b-instruct-hf
git git restore --progress --source=HEAD :/
转换格式以及量化
将模型转换为 llama.cpp 支持的 gguf 格式, 在 llama.cpp 目录下, 执行命令:
python3.10 convert.py models/codellama-7b-instruct-hf
完成之后会在 codellama-7b-instruct-hf 目录下生成对应的 gguf 文件。
量化
我的理解, 量化其实就是对模型就行适当的简化, 这篇文章 Quantize Llama models with GGUF and llama.cpp 说的很清楚, 建议使用 q5_k_m 模式进行量化。
llama.cpp/quantize models/codellama-7b-instruct-hf.f16.gguf models/codellama-7b-instruct-hf.q4_0.gguf q5_k_m
如果机器配置够高的话, 也可以不做量化,直接运行。 在 M1 Max 64G 内存的配置上, 可以直接运行 7b 参数级别的模型, 更多参数的模型则需要量化之后才能运行。
运行模型
命令行
在默认情况下, 将会调用模型输出一段文字,然后退出。
llama.cpp/main -m ./models/chinese-llama-2-13b-hf.q5_k_m.gguf
输出结果:
她将去中国,到一个没有互联网的地方。“我要去那里工作一段时间,把网络生活放在一边。”她说。 [end of text]
如果要交互式聊天, 需要添加一些参数, 示例如下:
llama.cpp/main -m ./models/chinese-llama-2-13b-hf.q5_k_m.gguf -c 512 -b 1024 -n 256 --keep 48 \
--repeat_penalty 1.0 --color -i \
-r "User:" -f prompts/chat-with-teacher.txt
llama.cpp/main --interactive-first \
--model ./models/chinese-llama-2-13b-hf.q5_k_m.gguf \
--temp 0.2 \
--keep -1 \
-f prompts/chat-with-baichuan.txt \
-r "用户:"
llama.cpp/main --interactive-first \
--model ./models/chinese-llama-2-13b-hf.q5_k_m.gguf \
--temp 0.2 \
--keep -1 \
-f prompts/chat-with-teacher.txt \
-r "\n学生:"
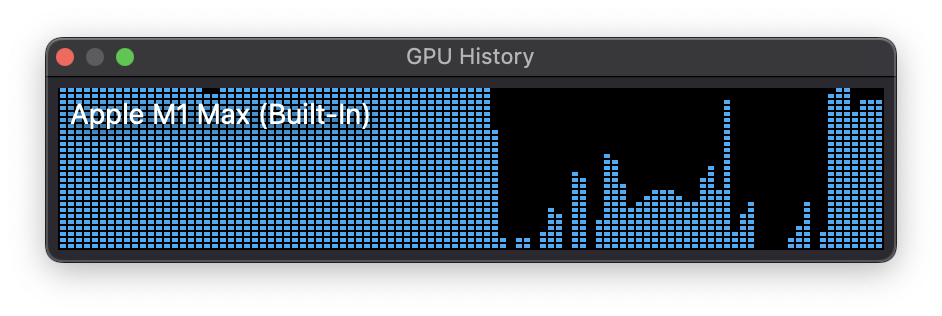
运行模型的时候, 在 GPU 历史窗口, 可以看到显卡是拉满的, 截图如下:
服务端
llama.cpp 还提供了与 open-ai 兼容的服务端 llama.cpp/server, 使用示例如下:
llama.cpp/server --host 0.0.0.0 --port 8080 \
--ctx-size 2048 \
--n-predict -1 \
--model ./models/codellama-7b-instruct-hf.f32.gguf
服务端运行起来之后, 就可以脱离命令行, 进行 API 调用或者使用 Postman 之类的 http 测试工具进行测试。
Web 客户端
llama.cpp/server 默认的界面非常简单, 只能说是测试用, 用浏览器访问 http://localhost:8080/ 可以看到, 这里就不截图了, 太丑。
但是, llama.cpp/server 提供的 API 是与 open-ai 兼容的, 很多第三方的 ChatGPT 客户端都可以使用, 比如 ChatGPT-Next-Web , 稍微查看了它的说明, 只要调整一下参数就可以直接运行它的 Docker 镜像, 无需任何修改:
docker run -it --rm \
--name chatgpt-next-web \
--publish 3000:3000 \
--env OPENAI_API_KEY=1234567890 \
--env BASE_URL=http://192.168.3.232:8080 \
yidadaa/chatgpt-next-web
-
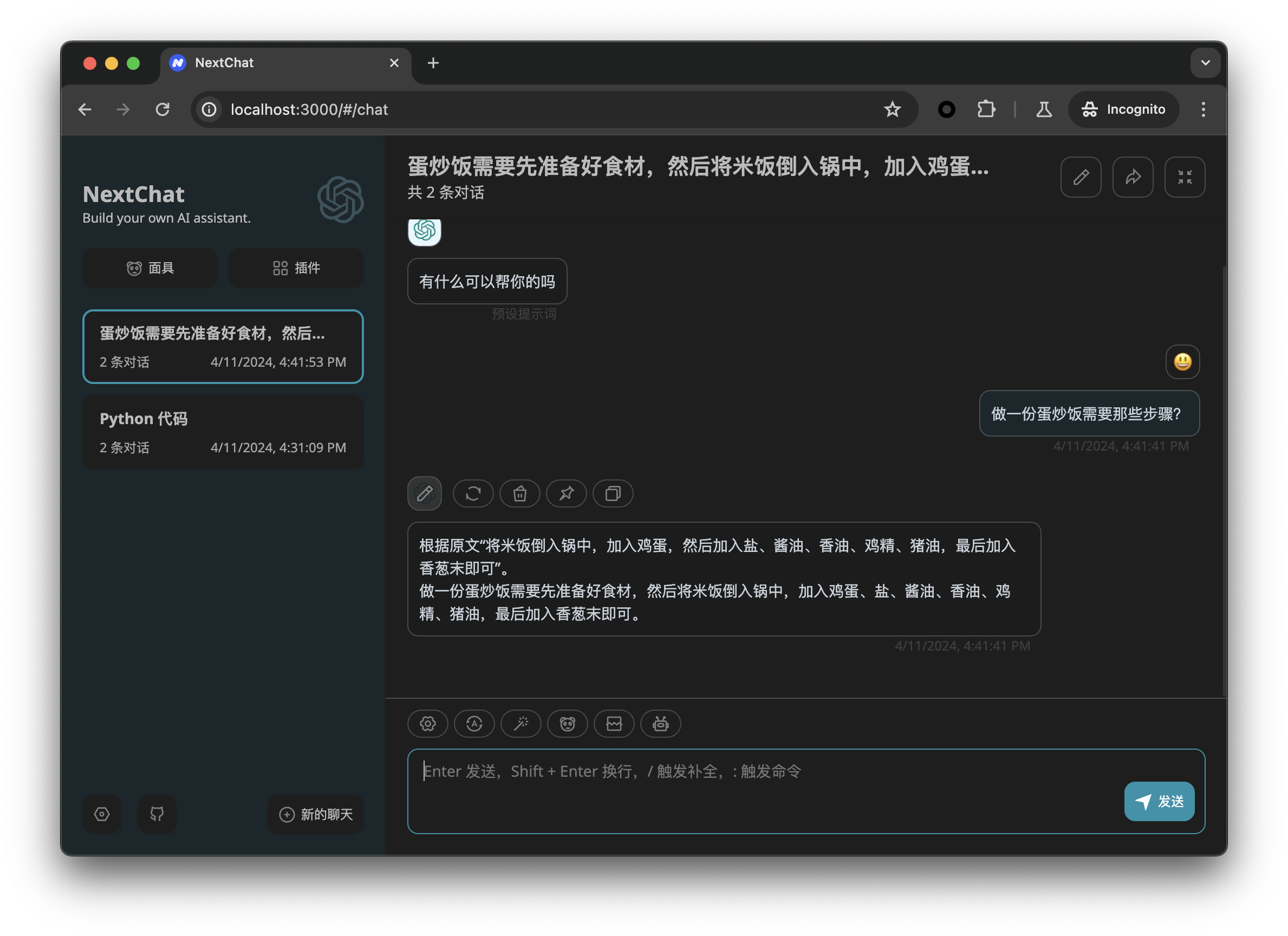
服务端使用运行
codellama-7b-instruct, 在客户端询问代码相关的问题, 截图如下: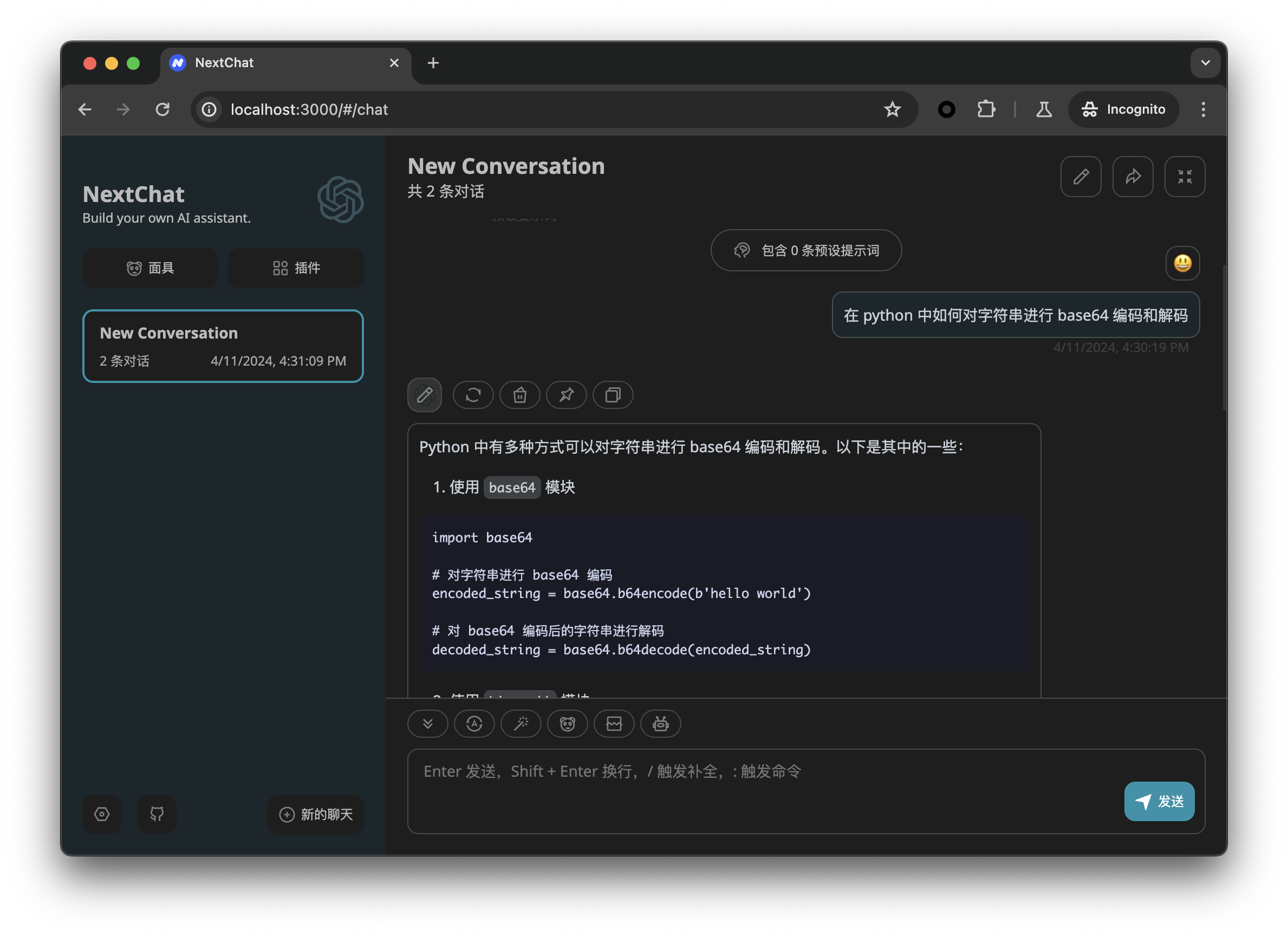
-
在服务端运行
01-ai/Yi-34B-200K, 在客户端询问常规问题, 截图如下: