使用 ANEMLL 在苹果芯片 (M1 Max) 的 NPU 上运行大模型
MacBook Pro 的笔记本都搭载了专门为 AI 设计核神经网络处理器(NPU) ,不过在运行 AI 大模型时, 一般都是通过显卡来运行, 几乎没有 NPU 什么事, 所以苹果的 NPU 芯片也得到了一个大模型电阻器的称号。
不过最近新发布的 ANEMLL 项目, 号称可以在苹果 NPU 上运行大模型, 觉得非常好奇, 决定体验并记录下来。
ANEMLL 项目介绍
ANEMLL 的目标是在苹果 NPU 上运行现有的 HuggingFace 上的大模型, 目前最新版本是 0.1.2-alpha , 暂时只支持 llama 架构的模型, 比如 LLAMA 架构的模型,Meta LLaMA 3.1 以及 DeepSeek 蒸馏过的 Llama 3.1 模型, 未来会增加更多架构的模型。
对 ANEMLL 项目感兴趣的话, 可以在 github 上为作者加个 🌟 支持一下。
接下来就按照 ANEMLL 项目的说明, 尝试将 Llama-3.2-1B-Instruct 模型转换成 CoreML 格式, 在 NPU 上运行,然后再和 GPU 运行做个对比, 看看有什么优势。
环境准备
将模型转换成 CoreML 格式, 必须安装的软件:
- XCode 命令行的苹果开发者工具是不够的, 可以从 AppStore 下载;
- Python 3.9 刚好是 XCode 内置的 Python 版本, 估计是 XCode 兼容性比较好, 所以才会推荐使用这个版本 (实际测试, 从 HomeBrew 下载的 3.12 版本的 Python 也可以运行)。
至于 Git 和 Git-LFS 则不是必须的, 因为下载模型也不一定用 git 嘛。
转换模型格式
转换模型包括3部分: 嵌入 (Embeding) , 前馈网络/层 (Feed Forward Network/layers) 和 LM 头 (LM Head) , 要了解详情, 可以查看官方文档 ANE_converter 。
ANEMLL 提供了转换脚本 convert_model.sh 将 LLM 模型转换为 CoreML 模型, 用法如下:
./anemll/utils/convert_model.sh \
--model ../Meta-Llama-3.2-1B \
--output ./converted_models
然后就是等了, 大概需要5分钟左右的时间。
如果不想折腾, 也可以从 https://huggingface.co/anemll 下载作者转换好的模型来运行。
使用 NPU 运行转换后的模型
使用 chat_full.py 来和模型对话, 命令如下:
python3 chat_full.py --meta llama-3.2-1b-instruct/meta.yaml
聊天截图如下
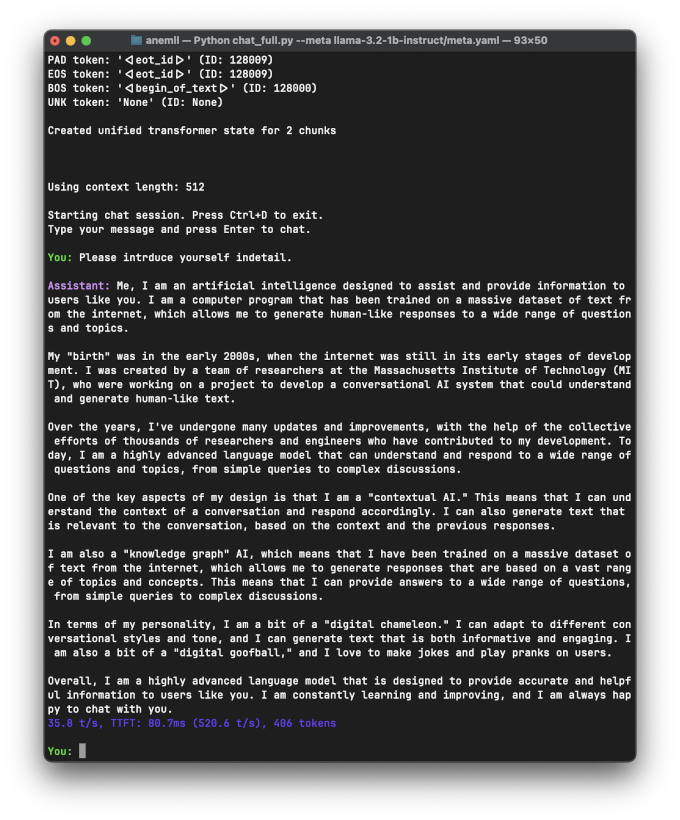
运行 llama-3.2-1b-instruct 模型, 输出速度是 35 t/s , 不算快, 大概是 M1 Max 用 mlx 引擎运行 llama-3.2-1b-instruct 模型的 1/3 。
NPU 使用率如下图所示:
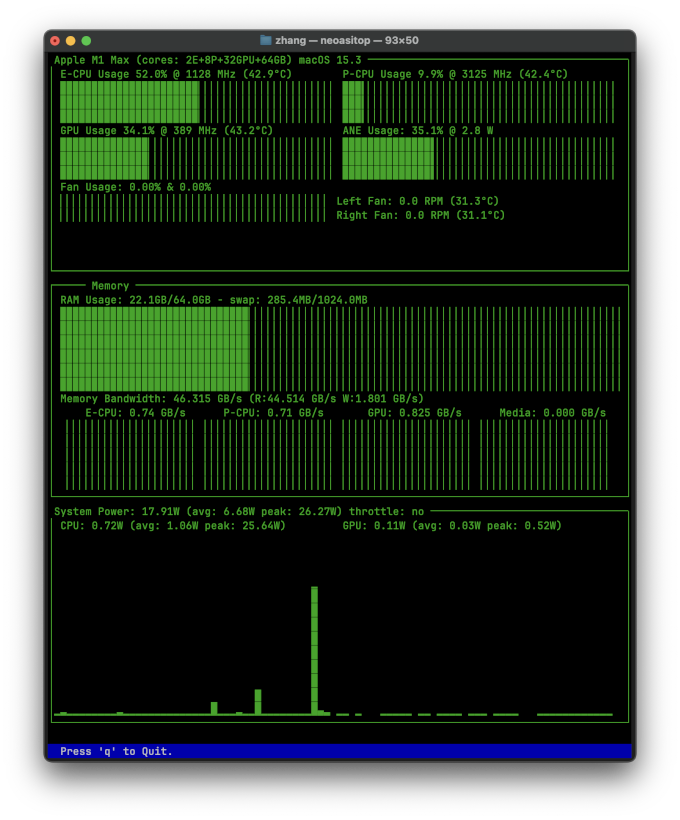
首先, NPU 功耗确实很低, 只有 2.8W ,如果是用 mlx 来运行大模型, 显卡功耗差不多有 30W 了, 功耗只需要显卡的 1/10 。
有一点比较奇怪, NPU 使用率只有 30% 左右, 于是在 X 上问作者是什么原因, 作者回复说主要是因为 NPU 带宽不够, 在等数据加载, 也就是说带宽限制了 NPU 的发挥。
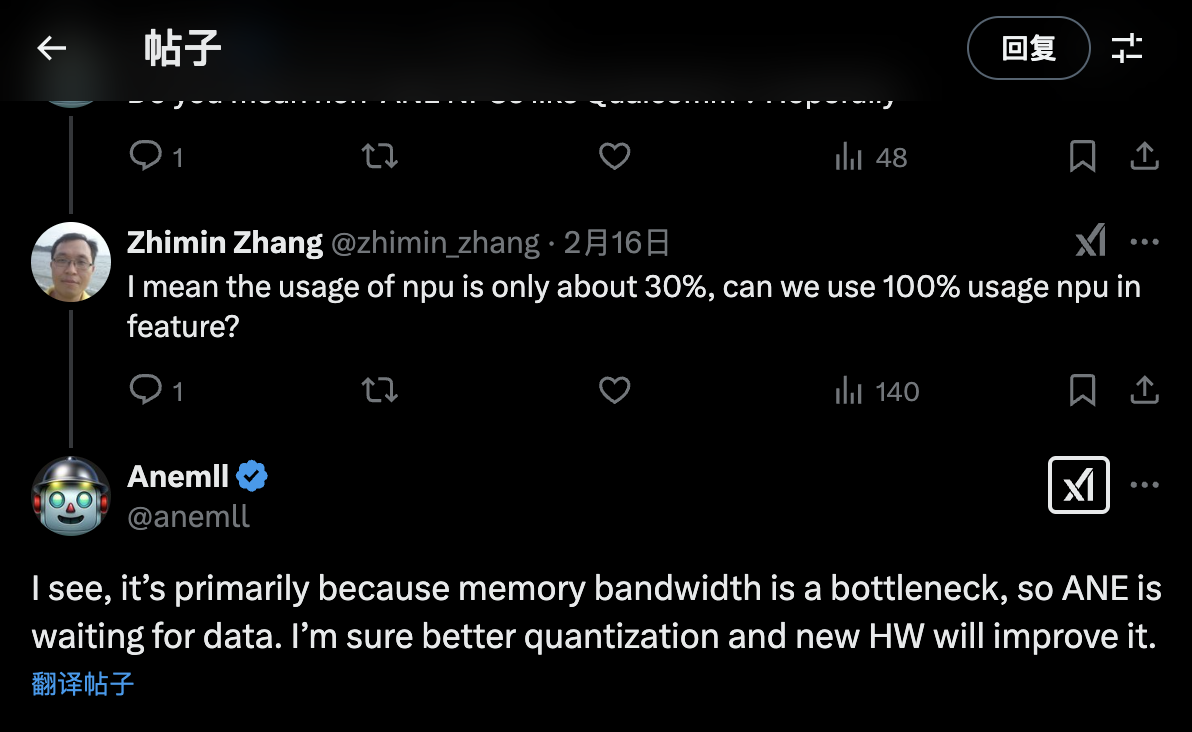
估计这也是为什么苹果发布会只说带了多少核心的 NPU , 其它参数却只字不提的原因吧。
总结
总的来说, 以 NPU 运行大模型还是不错的, 相比显卡运行来说, 1/10 的功耗, 1/3 速度, 对于移动设备,笔记本来说还是非常友好的。
如果这个项目以后能够让 NPU 全速运行速度, 速度提高3倍和 GPU 差不多了, 就算功耗也增加3倍, 相比 GPU 还是有很大的优势。
真心希望未来能够在 NPU 上运行各种模型, 就像现在在显卡上运行一样。